[AWS] DynamoDB - Query vs Scan
Query vs Scan
Query
★ Primary Key를 사용하여 데이터 검색
★Query 사용시 모든 데이터(컬럼) 반환
★ ProjectionExpression 파라미터
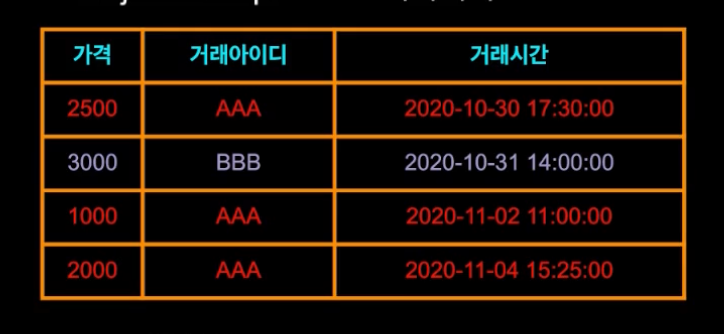
슈퍼마켓에서 물건을 팔 때 물건을 스캔하면 그 아이템의 가격, 거래 아이디, 언제 팔렸는지 기록이 남는다고 가정하자.
데이터를 쿼리할 때 거래 아이디 AAA를 사용한다면 우리는 데이터베이스에 들어있는 거래 아이디 AA에 해당하는 모든 데이터를 같이 가져온다는 뜻
여기서 모든 데이터란 모든 컬럼을 의미 : 아이템의 가격, 거래 아이디 그리고 언제 팔렸는지(거래 시간) etc
만약 쿼리를 돌려서 나오는 결과가 여러 개라면 사용자는 추가적으로 정렬키를 제공하여 사용자가 정말 필요로 하는 데이터만을 추출
쿼리는 프라이머리 키와 정렬키에 맞는 데이터의 모든 컬럼을 다 반환 시킨다.
그러나 프로젝션 익스프레션이라는 파라미터를 사용하여 사용자가 보고 싶은 컬럼만 볼 수 있게 수정 가능

위 테이블로 예를 들자면 프로젝트 익스프레션의거래 아이디와 아이템의 가격만 보여달라고 요청 가능 : 일종의 필터링 역할
Scan
★ 모든 데이터를 불러옴(Primary Key 사용❌)
스캔은 우선 모든 데이터를 다 가져온 다음에 따로 필터를 추가하여 사용자가 원하는 데이터를 보여준다.
Query는 데이터를 가져올 때 이미 partition이 적용되는 반면, Scan은 그렇지 않다.
★ ProjectionExpression 파라미터을 활용하여 우리가 원하는 정보를 볼 수 있다.
Query vs Scan
★ Query가 Scan보다 훨씬 효율적임
★ 따라서 Query 사용 추천
스캔은 우선 모든 데이터를 다 가져온 다음에 따로 필터를 추가하여 사용자가 원하는 데이터를 보여준다. ⮕ 데이터의 크기가 일정치 않다.
데이터가 쌓이고 테이블의 크기는 엄청 커진다면 Scan의 퍼포먼스는 악화. 쿼리 속도 ⭣
Scan의 보완
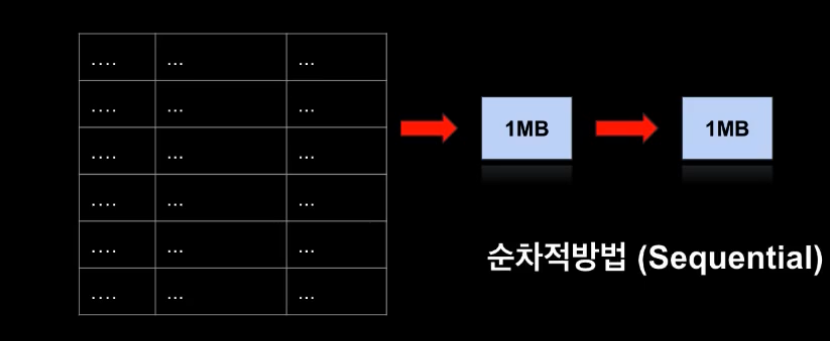
Scan을 할때 한번에 1MB에 해당하는 데이터를 가져온 다음 1MB에 해당하는 스캔결과(batch)를 가져온다. 이것을 순차적 방법이라함. (Sequential)
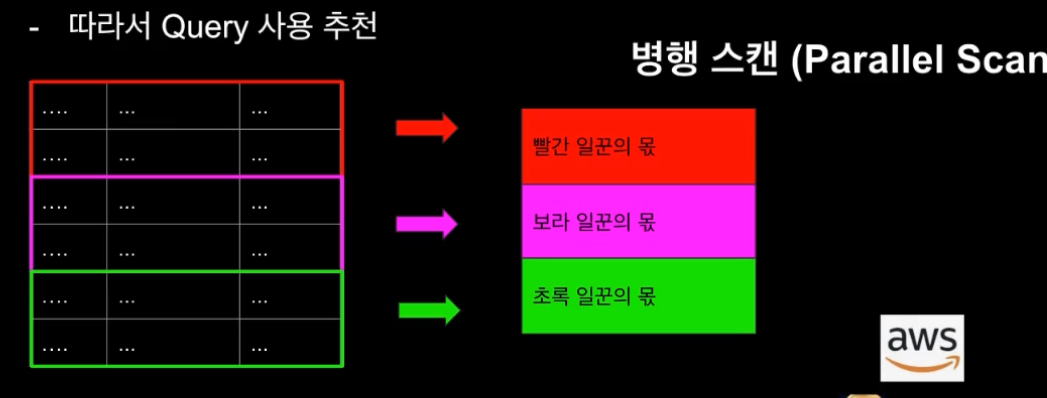
Scan을 할 때 여러개의 스캔 일꾼들을 여러 군데 분산시켜 병행시키는 기능이 있다. 그럼 스캔 속도가 빨라진다. 이것을 병행 스캔(Parallel Scan)이라고 한다. 테이블 전체를 n등분으로 쪼갠 다음 스캔 일꾼들을 쪼개진 파편으로 보내 동시다발적으로 스캔하라라는 것
이럴때 스캔을 써라.
만약 테이블 크기가 상대적으로 크지 않고 테이블의 프라이머리 키에 대한 정의가 필요없는 (즉, 룩업 용도) 용도로 사용되는 테이블을 보고 싶은 경우

바나나가 AB4K, 체리는 I42W 이런 상품 고유 코드를 담고 있는 룩업테이블은 크기가 많이 크지 않을 것이다.
심지어 프라이머리 키도 없을 것이다.
Lookup 테이블이란? 실시간으로 데이터가 계속 업데이트 되는 테이블과 는 달리 단순히 참고용으로 데이터 딕셔너리를 정의하고 보관하는 용도로 사용되어 지는 테이블
대부분 Lookup 테이블은 데이터의 중복이 거의 일어나지 않는다.